推荐下载
-
2020-05-12 浏览:789
-
2020-04-04 浏览:654
-
2020-05-06 浏览:560
-
2020-05-08 浏览:545
-
2020-05-12 浏览:543
DDL创建数据库,表以及约束(极客时间学习笔记)
发布时间:2021-05-01DDL是DBMS的核心组件,是SQL的重要组成部分. DDL的正确性和稳定性是整个SQL发型的重要基础.
DDL的基础语法及设计工具DDL的英文是Data Definition Language,也就是数据定义语言.定义了数据库的结构和数据表的结构.常用的功能急救室增删改,对应的命令分别是CREATE、DROP和ALTER.
对数据库进行定义
CREATE DATABASE nba; // 创建名为nba的数据库 DROP DATABASE nba; // 删除名为nba的数据库对数据表进行定义
CREATE TABLE table_name; // 创建表,table_name指表名创建表的结构呢? 举个实际的例子, 我们创建一个球员表, 表名为player, 里面有两个字段, 一个是player_id, 它是int类型,另一个是player_name字段是varchar(255)类型, 两个字段都不能为空, 并且player_id是递增的.
接下来创建表的语句这么就是:
CREATE TABLE player( player_id int(11) NOT NULL AUTO_INCREMENT, player_name varchar(255) NOT NULL );注意的是每个字段定义的语句最后使用 , 作为结束符, 最后一个字段的定义结束之后没有逗号的 , 并且语句最后是以 ; 结尾的. 数据类型中int(11)代表整数类型, 显示长度是11位, 括号中的参数11代表的是最大有效显示长度, 与类型包含的数值大小无关. varchar(255)代表的是最大长度为255的可变字符串类型. NOT NULL表名整个字段不能为空值,是一种数据约束. AUTO_INCREMENT代表主键自动增长.(一般情况下使用可视化工具类创建和操作数据库和数据库表,比如Navicat)
接下来针对player表,设计下面字段:
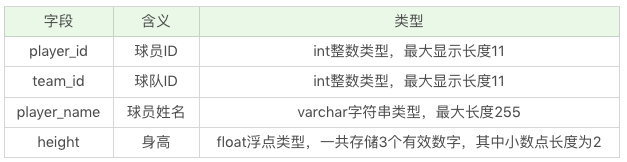
其中player_id是数据表player的主键, 且自动增长, 也就是player_id会从1开始, 然后每次加一, 不必为它赋值. player_id、team_id、player_name这三个字段均不为空, height字段可以为空.
使用Navicat工具创建表并导出的SQL文件如下所示:
DROP TABLE IF EXISTS `player`; CREATE TABLE `player`( `player_id` int(11) NOT NULL AUTO_INCREMENT, `team_id` int(11) NOT NULL, `team_name` varchar(255) CHARACTER SET utf8 collate utf8_general_ci NOT NULL , `height` float(3,2) NULL DEFAULT0.00, PRIMARY KEY(`player_id`) USING BTREE, UNIQUE INDEX `player_name`(`player_name`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;可以看到整个SQL文件中的DDL处理, 首先删除player表(如果数据库中存在该表的话), 然后再创建player表, 里面的字段名和表名都使用了反引号,这是为了避免名称与MYSQL保留字段相同,对数据库表和字段名都加上反引号.
其中player_name字段的字符集是utf8, 排序规则是utf8_general_ci, 代表对大小写不敏感, 如果设置为utf8_bin, 表示对大小写敏感.
因为player_id设置为了主键, 所以在DDL中使用PRIMARY KEY进行规定,同时索引方法采用BTREE.
对player_name字段进行索引, 在设置索引时, 可以设置UNIQUE INDEX(唯一索引), 也可以设置为其它索引方式, 比如NORMAL INDEX(普通索引), 这里我们采用UNIQUE INDEX. 唯一索引和普通索引的区别在于对字段进行了唯一性约束. 在索引方式上, 可以选择BTREE和HASH, 这里采用BTREE方法进行索引.
整个数据表的存储规则采用InnoDB, 是MYSQL5.5之后的默认存储引擎, 将字符集设置为utf8, 排序规则设置为utf8_general_ci, 行格式为Dynamic, 就可以定义数据表的最后约定了:
ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; 修改表结构创建完表之后, 可以对表结构进行修改, 使用DDL命令来完成.
添加字段
ALTER TABLE player ADD (age int(11));修改字段名, 将age字段改成player_age
ALTER TABLE player RENAME COLUMN age to player_age;修改字段的数据类型
ALTER TABLE player MODIFT (player_age float(3,1));删除字段, 删除刚才添加的player_age字段
ALTER TABLE player DROP CLOUMN player_age; 数据表的常见约束在创建数据表的时候, 会对字段进行约束, 约束的目的在于保证RDBMS里面的数据的准确性和一致性.
主键约束
主键起的作用是唯一标识一条记录, 不能重复, 不能为空, 即UNIQUE + NOT NULL. 一个数据表的主键只能有一个. 但是主键可以是一个字段, 也可以是多个字段符合组成. 上面的player_id就是主键.
外键约束
外键起的作用是确保表与表之间引用的完整性. 一个表中的外键对应了另外一张表中的主键. 外键可以重复并且可以为空. 比如player_id是player表的主键,如果想设置一个球员比分表player_score, 可以再player_score中设置player_id为外键,关联到player表.
唯一约束
唯一约束就是表明字段在表中的数值唯一, 主要是对除主键以外的其他字段(主键自带数值唯一BUFF). 上面对player_name进行了唯一性约束,也就是说球员的姓名不能相同. 注意的是唯一性约束和普通索引(NORMAL INDEX)之间的区别: 唯一性约束相当于创建了一个约束和普通索引, 目的是保证字段的正确性, 而普通索引只是提升数据检索的速度, 并不对字段的唯一性进行约束.
NOT NULL约束
对字段定义了NOT NULL, 表明字段不能为空, 必须有取值.
DEFAULT
表明字段的默认值, 如果在插入数据的时候该字段没有取值, 就设置为默认值.
CHECK约束
用来检查特定字段取值范围的有效性, CHECK约束的结果不能为FALSE.
设计数据表的原则"三少一多的原则":
数据表的个数越少越好
RDBMS的核心在于对实体和联系的定义, 也就是E-R图(Entity Relation Diagram), 数据表越少, 说明实体和联系设计得越简洁, 即方便理解有方便操作.
数据表中的字段个数越少越好
