前言
一直想学习开发一款小程序,无奈拖延至今,恰逢王者荣耀周年庆,然后本人对王者英雄的人物、配音比较感兴趣,就有开发一款王者荣耀故事站的小程序的念头。想要了解故事背景就直接打开小程序就好了。
ps: 因为是业余时间做的,所以 pc 端的爬虫数据展示方面就有点粗糙。
技术栈
小程序 + nuxt + koa2 + vue2.0 + vuex + nginx + pm2
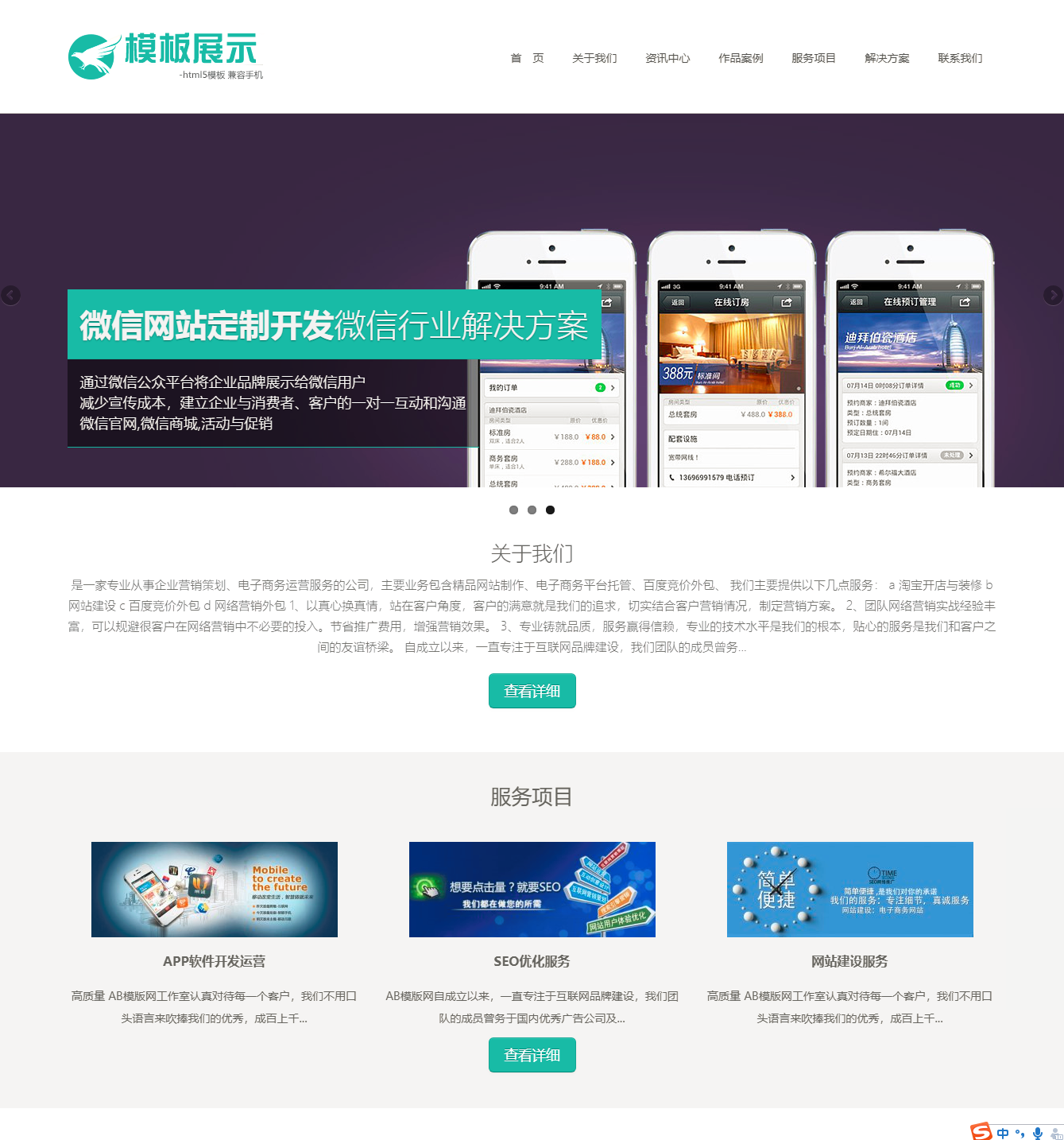
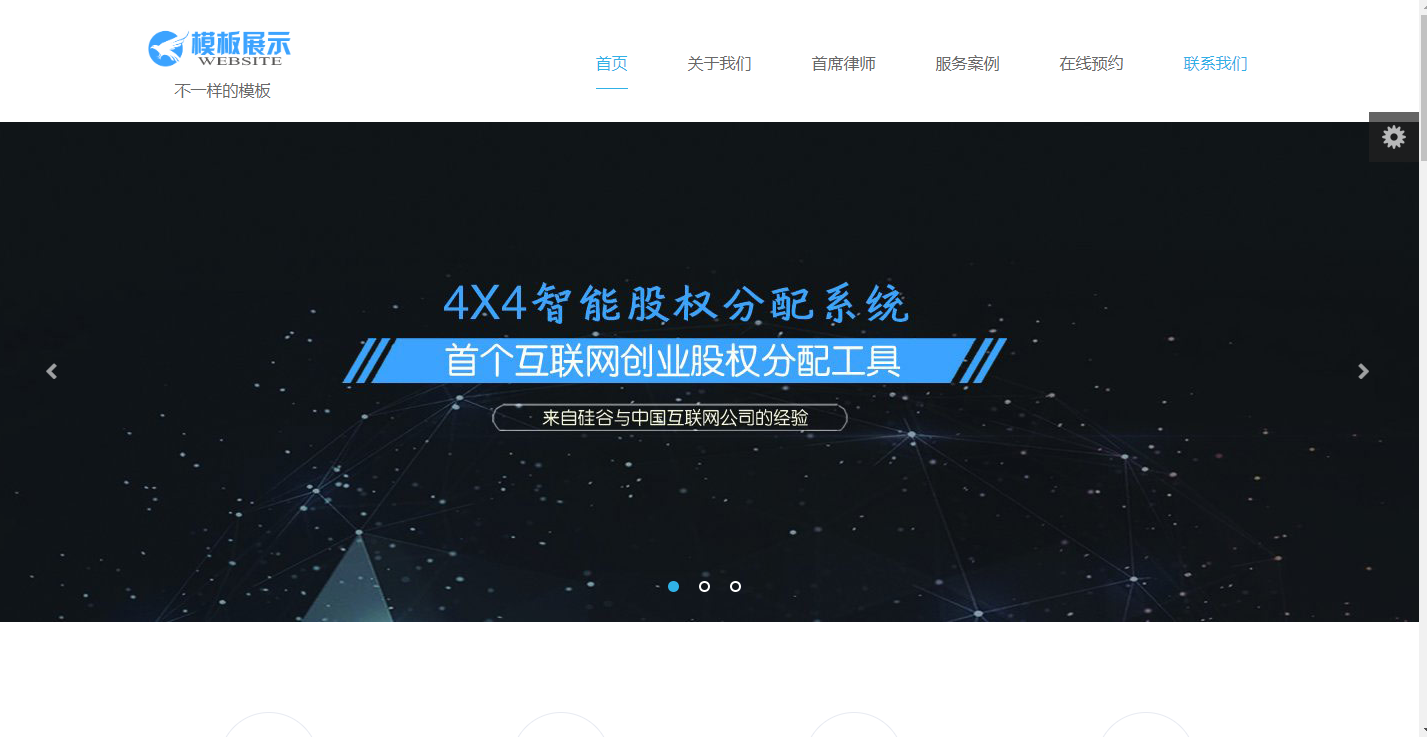
小程序效果图

线上体验

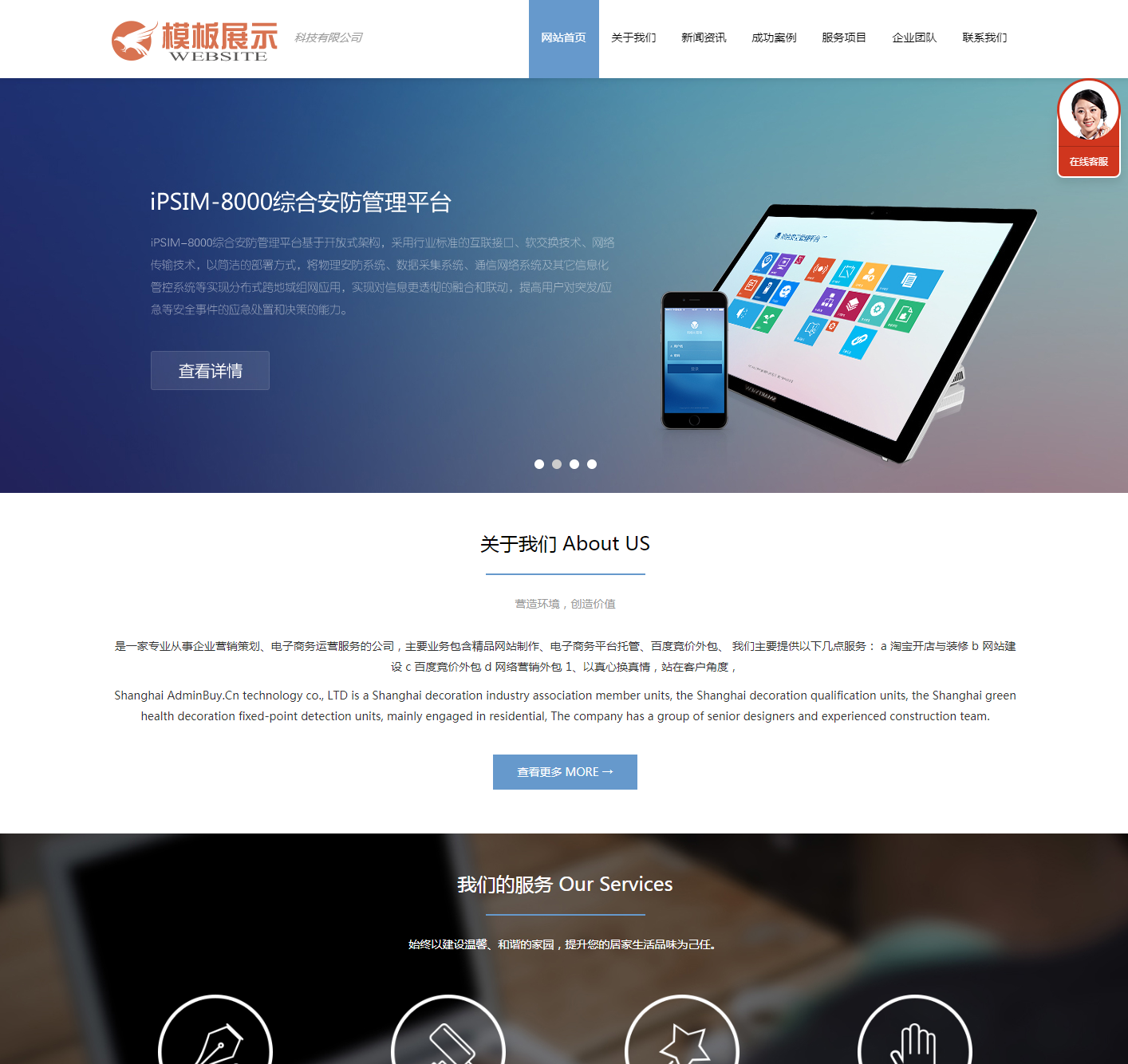
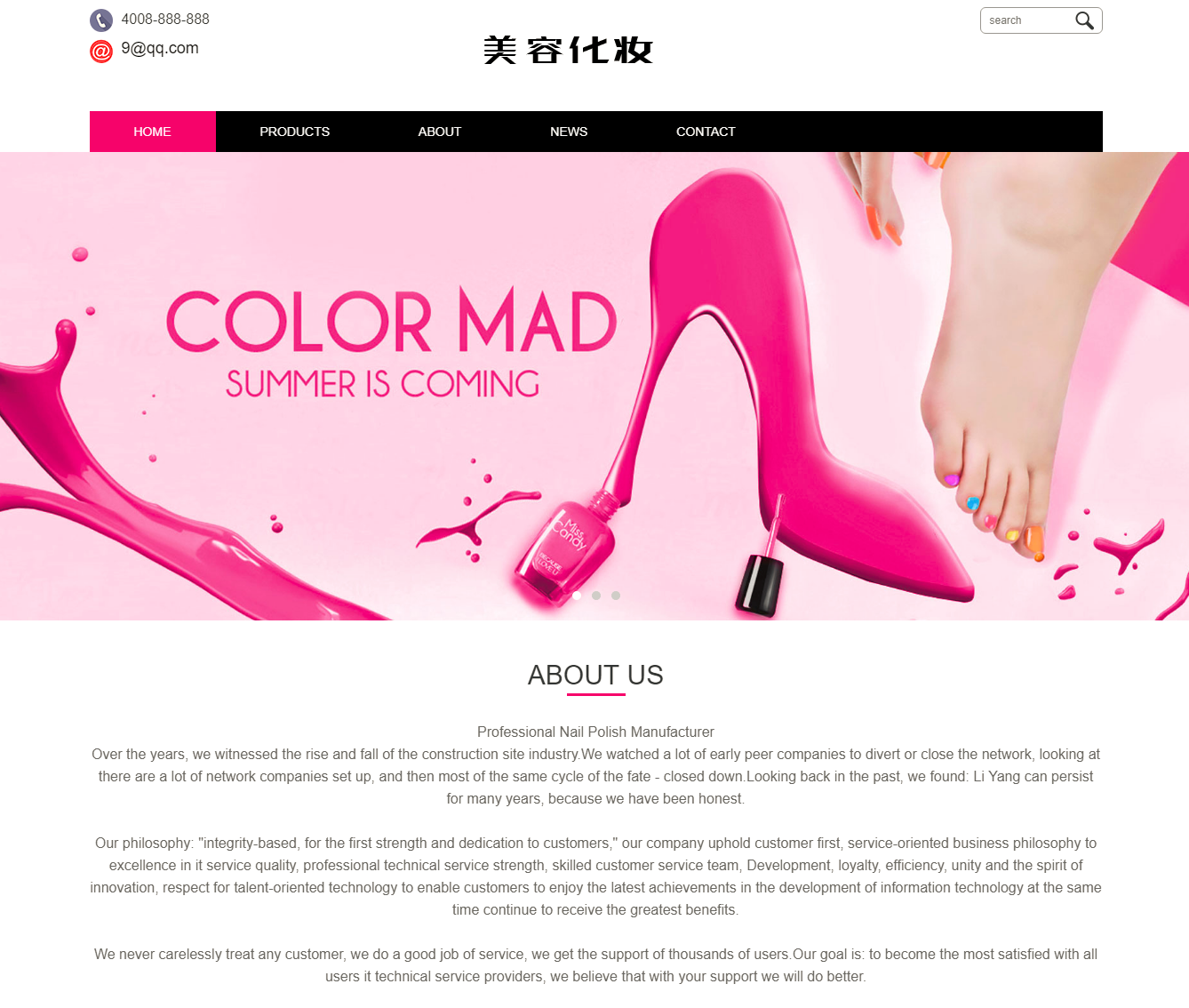
pc 爬虫效果图




线上地址
https://story.naice.me/
(如果觉得很慢的同学不是你们的网速的问题,是我的服务器配置太渣了2333)
首先说下爬虫数据
数据爬虫都是从王者荣耀故事站官网来爬取的,然后直接用 next/koa 作为后台,用cheerio模块和request-promise模块基本就可以爬到我们想要的数据了,有时候爬取出来的数据回事乱码(非 utf-8的)我们就借助iconv模块去转成我们想要的中文字符。这些模块说明文档在相应的 gihub中都说的很详细。就不一一介绍。
下面举例一下爬虫英雄列表首页的过程,都注释在代码里面
// 引入相应的模块
import rp
from 'request-promise'
import cheerio
from 'cheerio'
import { writeFileSync }
from 'fs'
const Iconv =
require(
'iconv').Iconv
const iconv =
new Iconv(
'GBK',
'UTF-8')
// request 国外网站的时候使用本地的 VPN
// import Agent from 'socks5-http-client/lib/Agent'
// 爬取英雄列表
const getHeroStory =
async() => {
// request-promise的配置
const options = {
uri:
'https://pvp.qq.com/act/a20160510story/herostory.htm',
// agentClass: Agent,
// agentOptions: {
// socksHost: 'localhost',
// socksPort: 1080 // 本地 VPN 的端口,这里用的 shadowsocks
// },
transform:
body => cheerio.load(body)
// 转成相应的爬虫
}
// 爬取导航复制给cheerio的$对象
const $ =
await rp(options)
let navArr = []
let heroList = []
$(
'#campNav li').each(
function () {
// 分析节点拿到数据
const type = $(
this).attr(
'data-camptype')
const text = $(
this).find(
'a').text()
// push 到navArr数组中
navArr.push({
type, text })
})
// 爬取英雄列表
const hreodata =
await rp({
uri:
'https://pvp.qq.com/webplat/info/news_version3/15592/18024/23901/24397/24398/m17330/list_1.shtml'
})
// 数据处理
let str = hreodata.replace(
'createHeroList(',
'')
str = str.substr(
0, str.length -
1)
let r =
JSON.parse(str)
heroList = r.data.filter(
item => item)
let result = {
nav: navArr,
heroList
}
// 写入文件
writeFileSync(
'./server/crawerdb/heroList.json',
JSON.stringify(result,
null,
2),
'utf-8')
return result
}
// 跟去英雄 id,和 url 爬取英雄的详细介绍
const getHeroDatail =
async(url, _id) => {
// 配置
const option = {
encoding:
null,
url
}
// 爬取英雄详情
const $ =
await rp(option).then(
body => {
// 字符乱码处理
var result = iconv.convert(
new Buffer(body,
'binary')).toString()
return cheerio.load(result)
})
// 这里拿到$之后就像 jq那样子,根据文档就可以进行爬虫的数据处理了
// 下面都是数据处理
let heroName =
''
let heroDetail = []
let ht =
''
let hc =
''
if ($(
'#heroStory').length) {
heroName = $(
'.hero_name pf').text()
$(
'#heroStory p').each(
function () {
let text = $(
this).text().trim()
heroDetail.push({
type:
'text',
text: text
})
})
}
else if ($(
'.textboxs').length) {
$(
'.textboxs p').each(
function () {
if ($(
this).find(
'img').length) {
let src = $(
this).find(
'img').attr(
'src')
heroDetail.push({
type:
'img',
text:
'https:' + src
})
}
else {
let text = $(
this).text().trim()
heroDetail.push({
type:
'text',
text: text
})
}
})
}
let hStr = ($(
'#history_content').text()).replace(
/(^\s+)|(\s+$)/g,
'');
if (hStr.length >
0) {
ht = $(
'.history_story h3').text()
hc = $(
'#history_content').text()
}
let result = {
heroName,
heroDetail,
historyTitle: ht,
historyContent: hc
}
// 写入文件
writeFileSync(
'./server/crawerdb/herodetail' + _id +
'.json',
JSON.stringify(result,
null,
2),
'utf-8')
return result
}
export default {
getHeroStory,
getHeroDatail
}
然后在 koa里面配置好路由就可以一步步爬取数据了
nuxt